 关于我
关于我 链滴
链滴 B3log
B3log
浏览数:
3446695
文章总数:
417
当前访客:5

已经删除了所有 QQ 好友
这周我把所有 QQ 好友全部删除了。 主要是真的太忙了,发消息过来我无法即时回复,然后放着放着就忘记了…… 因为扛不起这样的期待,所以选择了直接放弃,看到这条的朋友请多包涵。 如果要反馈我们产品的相关问题,请通过社区发帖或者 GitHub Issues,谢谢!

纯粹的 Markdown
Markdown 规范和扩展 Markdown 正是因为其简约和通用性才得以流行,通过 GFM/CommonMark 规范进行标准化以后 ,几乎宣称支持 Markdown 的平台和软件都已经做了实现。 目前来说,这是公认“纯粹”的 Markdown,没有那么多“花里胡哨”的东西。用户可以放心使用,通用性和迁移性能够在最大程度上得到保证。 但 GFM 规范不能满足一些“现代化”的使用需求,所以很多软件引入了一些扩展语法(比如上标下标、脚注、公式、图表等),这些扩展语法虽然不一定能在其他平台和软件上通用,但能够满足用户在该平台和软件上的特定需求,然后通过导出功能提供更广泛的格式支持。 前进还是倒退 在扩展语法的道路上越走越远以后,我们发现这似乎是在开历史的倒车。随着更多特定语法的引入,Markdown 的通用性逐步散失,就好像变成了特定软件的私有格式一般。更讽刺的是,语法引入却不能解决 Markdown 最大的问题 —— 自带资源文件(虽然 TextBundle/TextPack 做了一些努力,但就目前而言基本也还是不通用)。 越强大的功能,意味着越复杂的语法,如果沿着这条路一路走下去,语....

2020 但行好事莫问前程
本篇是我的 2020 年总结,也是《创业》系列的终章。 创业三年才是开始 2020 年是我和 V 创业的第三年。这三年我们主要靠 Sym 社区系统商业版过活,加上偶尔接的一些外包项目,年收入还算不错。虽然比较辛苦,但我们觉得自食其力蛮快乐的。 这三年来我们在产品方向上做了很多尝试。其中链书和星火目前看来并不成功,但也许以后还有机会继续下去。 去年八月份我们开始开发新产品思源笔记,经过半年的“夺命狂奔”,计划于 2021 年 2 月 19 日发布思源笔记 v1.0.0,这会是一个全新的开始。 慢一天都不行 在 2020 年双链笔记的风口热潮中,迅速涌现出了上百款笔记软件和平台服务。说实话,我几乎都没怎么去使用,只是走马观花安装或者注册试用了下。其中一些非常好的产品是那种一上手就能感受到的,比如 wolai 和 Obsidian,充满了强烈的设计感和流畅的操作体验。 我作为一个产品设计者,不认真体验类似产品显然是不合格的,但前期实在没有时间去了解这么多信息,主要还是靠自己的想法和社区群策群力,所以目前思源在很多交互逻辑上磕磕绊绊的,总觉得有些别扭难以上手。后续我们得花些时间进行打磨,理顺交....

创业的第三个秋天
如果你是第一次看这个系列的文章,可从第一《创业的第一个春天》 看起。 秋天是个忙碌的季节,码农们说。 黑客派改名链滴 社区定位发生了一些变化,不局限在程序员交流,希望有更多热爱生活的人加入。 记录生活,连接点滴 “连接点滴”目前还没有呈现出来,我们设想是通过博客端(Solo/Pipe)、笔记端(思源笔记)产品来构建分布式网络,各个端点可以离线工作,也能在线和社区端交互。内容数据将基于“块”的粒度进行封装,通过离线-在线融合组网,以内容块的形式构建应用场景。 更远的以后会尝试将内容块(Content Block)和区块链(Blockchain)结合,以去中心化、模块化的思路达成愿景。 思源笔记 这个秋天我们的主要精力聚焦在思源笔记(前身是链滴笔记)的开发上,目前已经完成了一些特性,总体框架上支持完全离线、在线同步、移动端/桌面端浏览器、版本管理等。在细节功能上,思源已经支持块级引用双向链接、支持 Markdown 即时渲染编辑。接下来我们会继续完善功能,继续打磨细节体验,做一款出色的 Markdown 笔记应用。 广告:虽然现在仍然处于早期阶段,但思源笔记已经开始销售了。前 512.......

创业的第三个夏天
如果你是第一次看这个系列的文章,可从第一《创业的第一个春天》 看起。 在炎热的夏天里,微风徐徐。虽然不能乘风破浪,但也能感受到些许惬意。 博客端 Solo 最大的改变就是去掉了内置的本地评论系统,引入 Gitalk 解决本地评论的需求。同时,被很多用户一直期待的 solo-blog 仓库同步功能回来了! 另外,社区端加强了博客端引流,进一步优化 B3log 分布式社区的流量分布。 黑客派 社区管理上发生了一件在我预期之外的事,结果导致一个荣誉会员注销账号。这让我想起了多年以前社区管理也出过一次问题,当时我的老板看到后在一次团建时私下和我说“做个‘家长’不容易吧”。现在看来,社区管理问题一直没有解决,我是最终责任人。 这样的问题如果持续发生,社区将很难发展。这就好比一个公司,如果运作出现问题,根本的原因在于决策者制定的机制有问题。继续探索吧,重点考虑贡献系统的改进,把理想化的规则在最大程度上适配到现实情况。 Sym 社区系统 Sym 商业版主要加入了主持人系统,让有版主需求的站点可以更方便地进行内容管理。后续计划是重写管理后台,加入数据统计分析功能,让运营者可以更方便直观地了解运营情况.....

Java 提取和删除照片图片 Exif GPS 等隐私信息
照片图片 Exif 通过手机相机或者数码相机拍摄的照片都带有 Exif 元数据信息,比如下面这张照片: 它的 Exif 信息为: 1Root: 2 ImageWidth: 4000 3 ImageLength: 3000 4 Make: 'Xiaomi' 5 Model: 'MI CC 9' 6 Orientation: 1 7 XResolution: 72 8 YResolution: 72 9 ResolutionUnit: 2 10 DateTime: '2019:12:16 13:49:17' 11 YCbCrPositioning: 1 12 ExifOffset: 210 13 GPSInfo: 770 14 15Exif: 16 ExposureTime: 1/295 (0.003) 17 FNumber: 179/100 (1.79) 18 PhotographicSensitivity: 112 19 Unknown Tag (0x8895): 0 20 ExifVersion: 48, 50, 50, 48 21 DateTimeOrigina....

创业的第三个春天
如果你是第一次看这个系列的文章,可从第一《创业的第一个春天》 看起。 创业第三个年头了,娃已经长大到会问我今天还有多少 issues 没改完。 博客端 将 Solo、Pipe 完整接入社区,文章浏览计数和评论使用了社区统一提供的服务组件: uvstat:实现浏览、评论统计 vcomment:实现评论集成展现 另外,Solo 实现了静态化用法,可以生成导出静态站点,方便用户部署到 GitHub Pages 上。 笔记端 链滴笔记实现了初版,目前已经基本满足了我个人在本地 Markdown 编辑排版的需要: 有的长文需要好几天才能写完,本地陆续写好后再粘贴到线上发布。以前主要用有道云笔记,现在已经迁移到链滴笔记 记一些琐碎的记录,比如常用命令、TODO 后面我们将开始实现导出静态化站点功能,逐步集成社区,作为社区的笔记端节点。 社区端 暗黑模式 黑客派上线了暗黑模式,已经支持全部主题。具体的主题模式有三种:明亮、暗黑和随日出日落自动切换。为了“随日出日落自动切换”,我整理了中国城市经纬度数据,有需要的朋友可自取。 对于命名,之前稍微纠结过一下到底是叫“夜间模式”还是“暗黑模式”。....
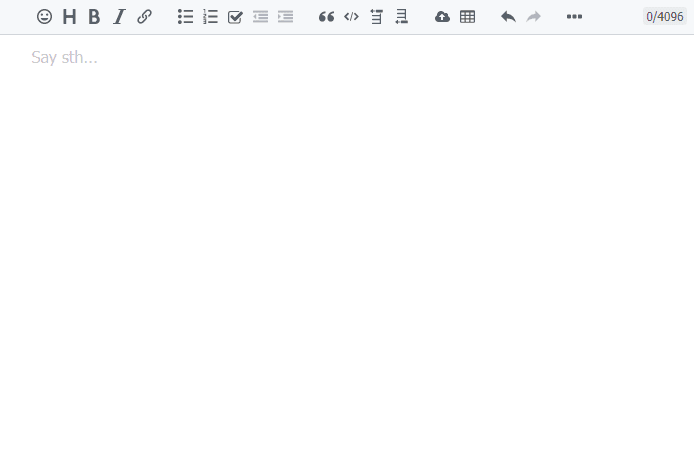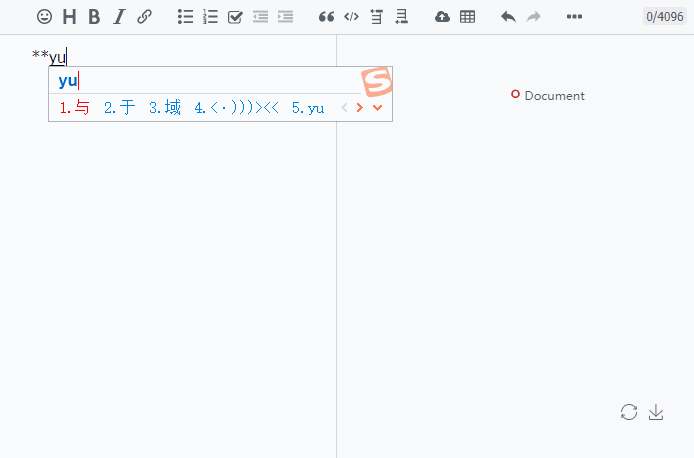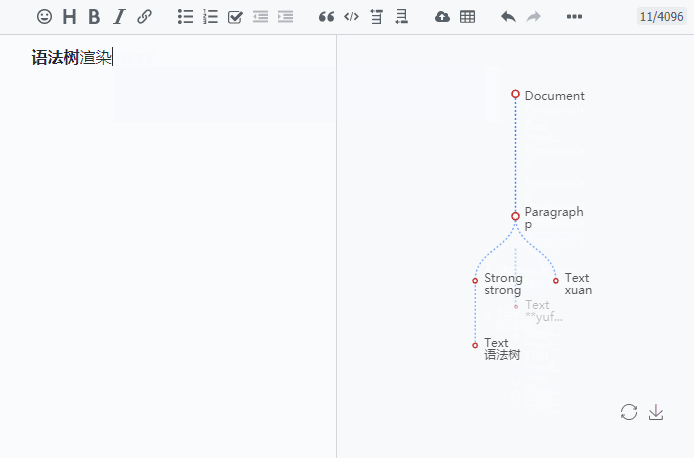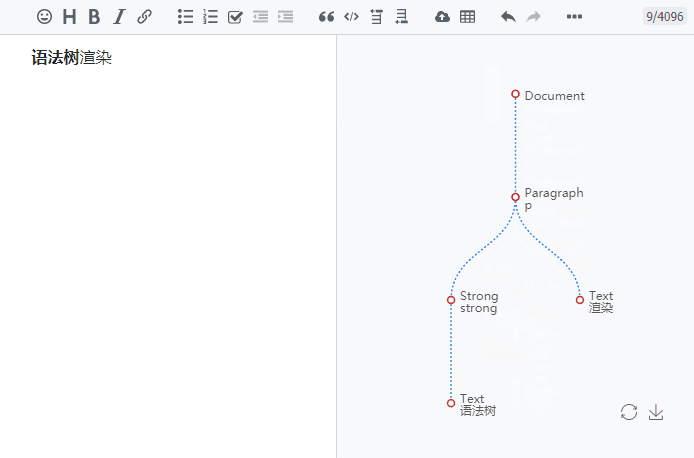
Markdown 解析原理详解和 Markdown AST 描述
概述 本文主要介绍 Markdown 引擎 Lute 的整体处理流程,并详细描述了 Markdown 抽象语法树结构。 编译原理 我们通过编译原理实现了 Lute ,大致步骤是预处理、词法分析、语法分析、代码生成这几个步骤。代码结构方面我们分为两部分,解析和渲染。 1// Markdown 将 markdown 文本字节数组处理为相应的 html 字节数组。name 参数仅用于标识文本,比如可传入 id 或者标题,也可以传入 ""。 2func (lute *Lute) Markdown(name string, markdown []byte) (html []byte) { 3 tree := parse.Parse(name, markdown, lute.Options) 4 renderer := render.NewHtmlRenderer(tree) 5 html = renderer.Render() 6 return 7} 解析过程用于从 Markdown 原文构造抽象语法树。 1// Parse 会将 markdown 原始文本字节数组解析为一颗语法树。 2f.......

Windows 10 搭建 TensorFlow 试玩 fast-style-transfer
本文适用于 TensorFlow 新手搭建试玩“图片快速风格迁移”,系统环境: Windows 10 显卡 NVIDIA GTX 1070 安装 TensorFlow 环境 用 Anaconda 来装环境可以省很多事。 安装 Anaconda,步骤中有两个选项记得勾上(添加 PATH 环境变量和使用 Anaconda 作为 Python 环境) 现在的 Anaconda 似乎已经内置了国内的几个镜像源,所以不用手动切换镜像,用默认配置即可 如果已经折腾过,可以考虑用如下命令恢复: conda config --remove-key channels conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --set show_channel_urls yes 如果你像我一样只是个入门玩家(并且平时没装过 Python 环境),那就不用搞 conda 的环境隔离了。直接执行 conda install tensorflow-gpu,....

创业的第二个冬天
如果你是第一次看这个系列的文章,可从第一篇《创业的第一个春天》[^1] 看起。 认真积累,别走捷径。 CDN 盗刷 12 月份的某天,社区的 CDN 图床被人恶意刷了好几十 G 流量,虽然造成的损失就几十块钱,但我觉得这不是钱的问题,而是对我技术能力的嘲讽。通过分析日志,基本可以判断攻击来源是类似基于 Electron、Headless Chrome 的应用,因为这些攻击流量的来源 IP 大部分不是来自机房服务器。 随后我们通过七牛云提供的“回源鉴权”机制解决了这个问题,所有对图床 CDN 的请求都需要鉴权。判断依据是通过 Referer、IP,大致规则是禁止为空的 Referer,并且 IP 不能来自机房。顺手也加了防盗链,综合了博客端节点(Solo、Pipe)回调接口来判断请求是否是博客端发起的。 后来攻击者发现我们的应对措施后,就将流量转移到了攻击博客端节点,一些用户的博客被恶意请求,请求并不密集,攻击者企图慢慢消耗社区图床 CDN 以造成损失。这部分攻击流量后来也通过限流算法做了判断,最终将不合法的 IP 加入到社区 IP 黑名单[^2]中,博客端节点会定时获取这份黑名单列表.....

Solo 从设计到实现后记
本文是《Solo 从设计到实现》的一个章节,该系列文章将介绍 Solo 这款 Java 博客系统是如何从无到有的,希望大家能通过它对 Solo 从设计到实现有个直观地了解、能为想参与贡献的人介绍清楚项目,也希望能为给重复发明重新定义博客系统的人做个参考 ❤️ 轮子和时间 “不要重复发明轮子”在程序员界的流行应该是从 Rod 发明 Spring 开始。他曾经在其著作《Without EJB》中使用了这个谚语,并阐述了 Spring 的诞生基于这一理念。 重复发明轮子最大的问题在于浪费时间。作为作者,浪费时间重复劳动;作为用户,浪费时间尝试。一个不好的轮子会严重浪费大家的时间,所以“不要重复发明轮子”主要针对的是那些不够圆的轮子而言。 新轮子肯定不会很圆。要么是设计问题,要么是工艺问题。设计问题最好在设计阶段就确认好,工艺问题可以花时间解决。 我觉得只要大家有时间,就尽可能发明轮子吧。无论是产品层面的优化改进,还是框架技术层面的创新尝试,我觉得都是值得的。作为普通程序员,浪费一些时间并没有什么大不了的,相信勇于尝试并坚持下去,一定能够改变一些事情的。 成功的开源 什么是成功 一个开源项目.....

搭建 GitHub 镜像仓库
需求背景 国内访问 GitHub 仓库实在太慢,项目主要提交者也就我和 V,外加以后打算自己建立仓库,所以决定在新项目上试试。 将 GitHub 仓库作为镜像仓库,主库设在自建的服务器上。这样既能获得 GitHub 协作特性(Issues、PR、Actions、Release 等),开发时又能享受高速提交和拉取。 服务端 创建 Git 用户,配置 git-shell 等,然后配置 SSH 密钥,密钥分为两类: 客户端提交服务端用,修改 ~/.ssh/authorized_keys 服务端自动推送 GitHub,修改 ~/.ssh/id_rsa.pub。GitHub 上需要配置账号 SSH 或者仓库 Deploy Keys 切换到 Git 用户,并在 ~ 下创建仓库 mkdir sample.git && cd sample.git && Git clone --bare [email protected]:youraccount/sample.git 在 hooks 目录下创建名为 post-receive 的脚本: #!/bin/sh g....
